




![]()
微信号复制成功
微信号:ganshangwoniu
请返回微信添加朋友,粘贴微信号
我知道了


使用阿里云服务器来进行数据爬取的具体步骤如下:
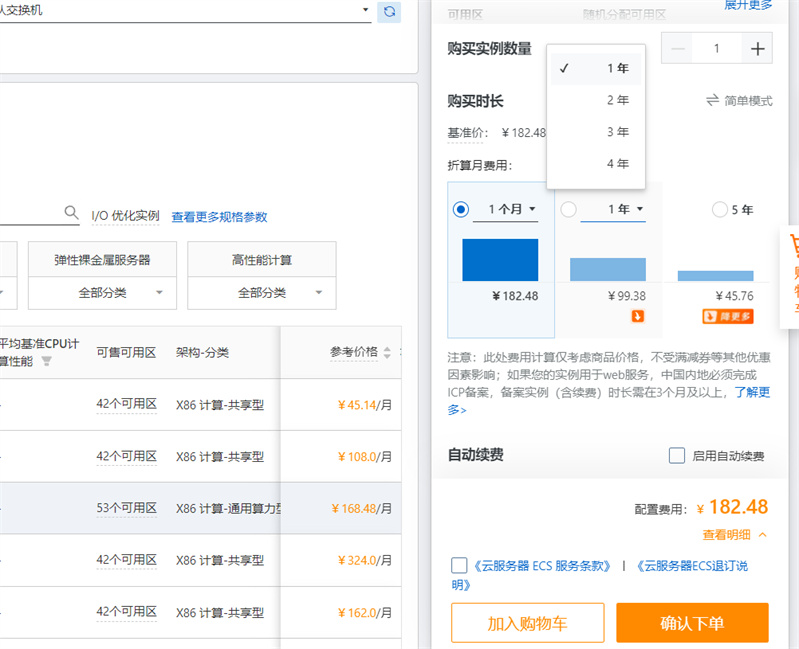
购买和配置服务器:在阿里云上购买一台适合你需求的服务器实例,并进行基本的配置,包括选择操作系统、网络设置等。确保服务器能够正常联网和访问目标网站。
远程连接服务器:使用SSH协议远程连接到服务器,可以使用SSH客户端工具或终端进行连接。输入服务器的公网IP地址和登录凭据进行连接。
安装和配置爬虫工具:在服务器上安装适合你爬虫需求的工具,如Python的爬虫框架Scrapy、BeautifulSoup等。通过命令行或终端使用包管理工具安装相应的软件。
编写爬虫代码:使用你熟悉的编程语言编写爬虫代码。根据目标网站的结构和数据抓取需求,使用相应的爬虫框架或库进行数据爬取。确保代码能够正常运行,并按照你的需求抓取到所需的数据。
设置爬虫参数和权限:根据目标网站的爬取策略和限制,设置爬虫的参数,如请求频率、User-Agent、Cookie等。如果需要登录或进行身份验证,需要额外设置相应的权限和认证信息。
运行爬虫程序:通过命令行或终端在服务器上运行爬虫程序。观察日志输出,确保程序正常运行并能够成功抓取数据。
数据存储和处理:根据你的需求,选择合适的方式进行数据存储和处理。可以将数据保存到数据库中或存储为文件。使用相应的数据处理工具对数据进行清洗、去重、分析等操作。
请注意,当使用爬虫进行数据抓取时,务必遵守相关法律法规和目标网站的爬取规则。尊重网站的隐私和访问限制,并避免对目标网站造成过大的访问负载。在进行数据爬取时,建议采用合理的爬取策略,设置适当的请求频率和监控机制,以避免造成服务器和目标网站的不必要压力。
另外,在使用阿里云服务器进行数据爬取时,建议关注服务器的安全配置,包括更新系统和软件补丁、设置防火墙和安全组规则等,以保护服务器的安全性。
QQ在线沟通,点击马上咨询在线咨询
电话咨询:
177-2050-9380
微信咨询:
ganshangwoniu

